Enhancing Articles Through Hyperlinks
When reading an article, I often run into a problem: there are links I want to open but now is not a good time to open them. Why is now not a good time?
- If I open them and read them now, I’ll lose the context of the article I’m currently reading.
- If I open them in the background now and come back to them later, I won’t remember the context that this page was opened from and may not remember why it was relevant to the original article.
I prototyped a solution – at the end of an article, I attach all of the links in the article to the end of the article with some additional context. For example, from my Android thread annotations post:
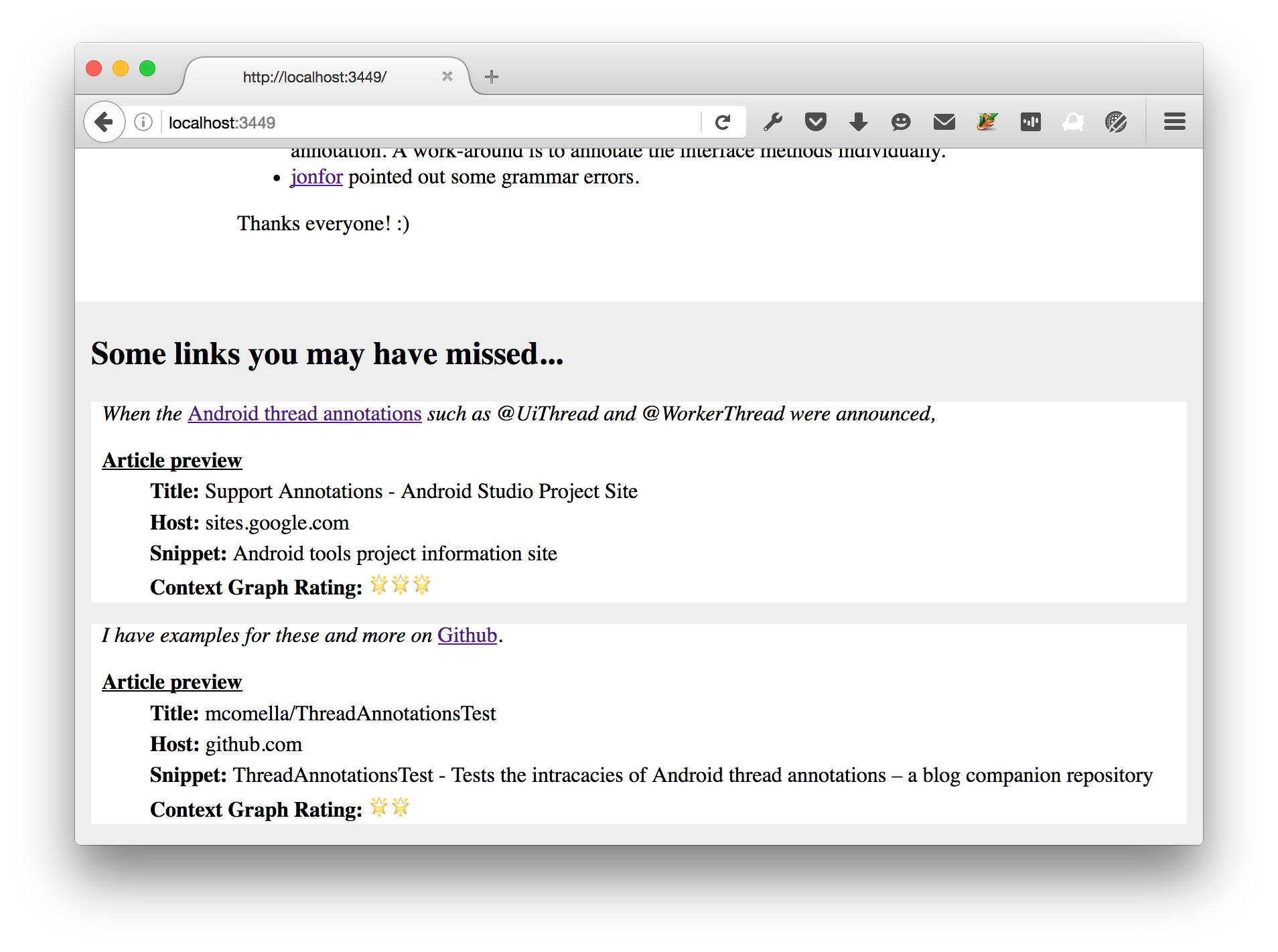
To remember why I wanted to open the link, I provide the sentence the link appeared in.
To see if the page is worth reading, I access the page the link points to and include some of its data: the title, the host name, and a snippet.
There is more information we can add here as well, e.g. a “trending” rating (a fake implementation is pictured), a favicon, or a descriptive photo.
And vice versa
You can also provide the original article’s context on a new page after you click a link:
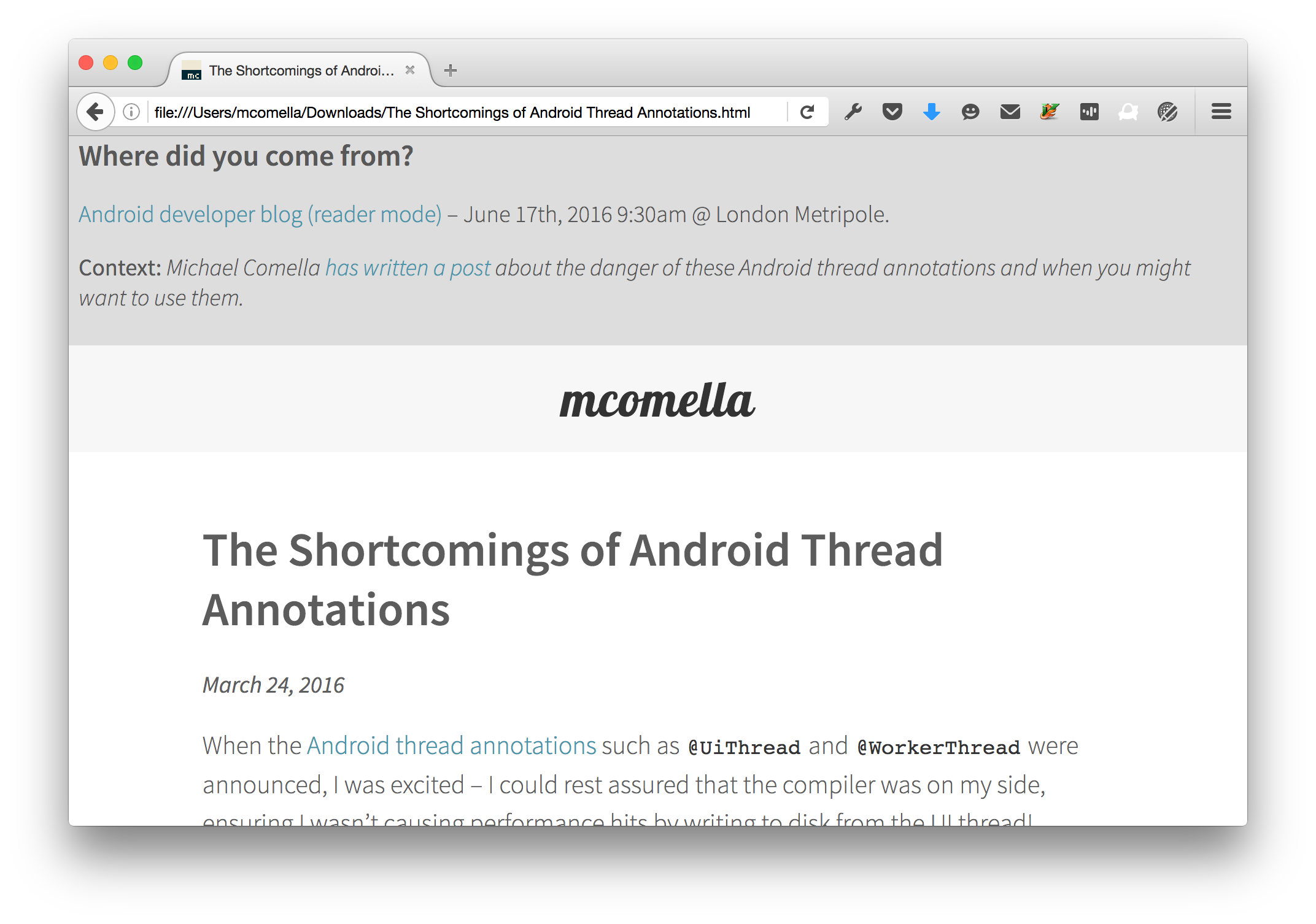
This context can be added for more than just articles.
Shout-out to Chenxia & Stefan for independently discovering this idea and a context graph brainstorming group for further fleshing this out.
Note: this is just a mock-up – I don’t have a prototype for this.
Themes
The web is a graph. In a graph, we can access new nodes, and their content, by traversing backwards or forwards. Can we take advantage of this relationship?
Alan Kay once said, people largely use computers “as a convenient way of getting at old media…” This is prevalent on the web today – many web pages fill fullscreen browser windows that allow you to read the news, create a calendar, or take notes, much like we can with paper media. How can we better take advantage of the dynamic nature of computers? Of the web?
Can we mix and match live content from different pages? Can we find clever ways to traverse & access the web graph?
This blog & prototype provide two simple examples of traversing the graph and being (ever so slightly) more dynamic: 1) showing the context of where the user is going to go and 2) showing the context of where they came from. Wikipedia (with a certain login-needed feature enabled) has another interesting example when mousing over a link:
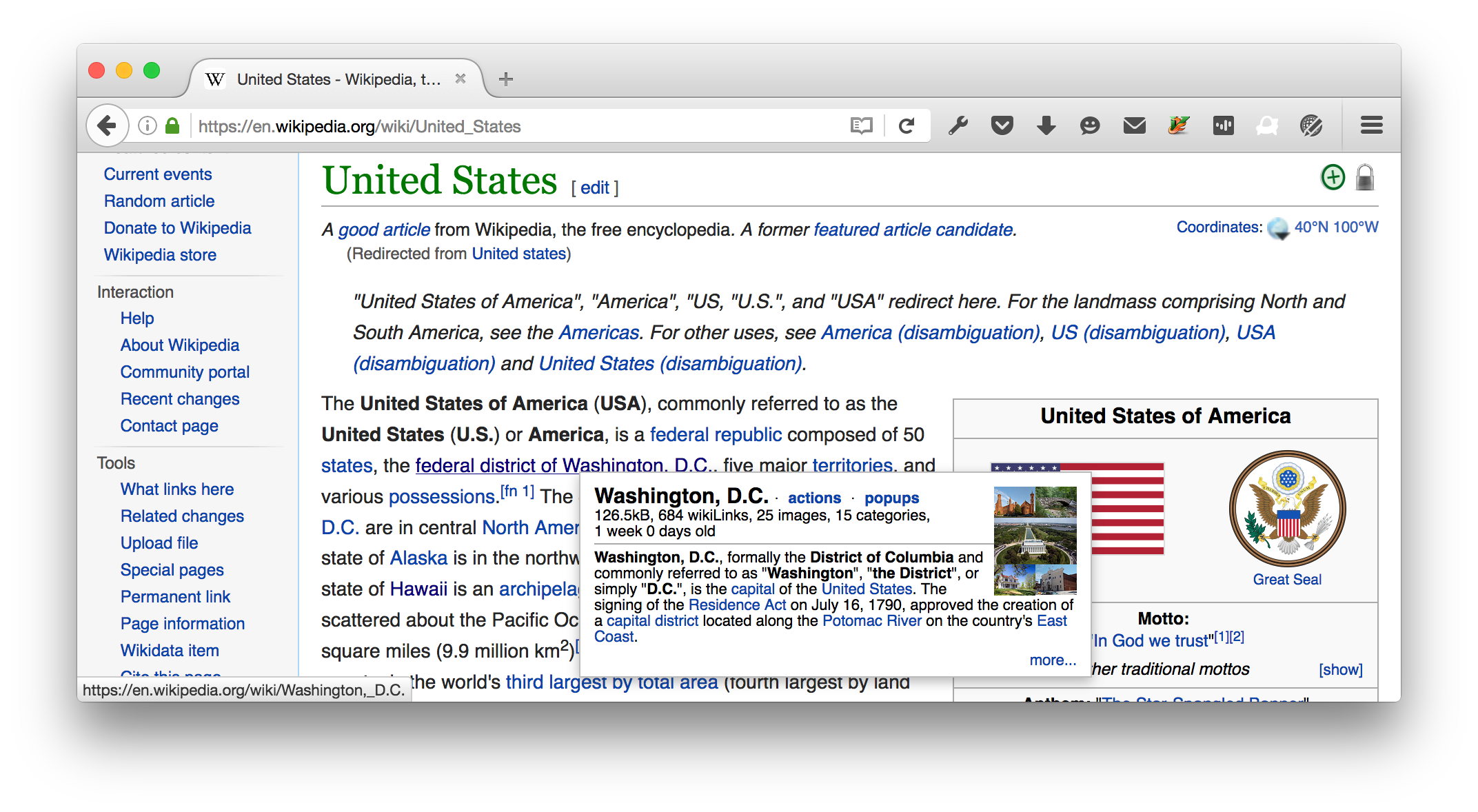
They provide a summary and an image of the page the hyperlink will open. Can we use this technique, and others, to provide more context for hyperlinks on every page on the web?
To summarize, perhaps we can solve user problems by considering:
- The web as a graph – accessing content backwards & forwards from the current page
- Computers & the web as a truly dynamic medium, with different capabilities than their print predecessors
For the source and a chance to run it for yourself, check out the repository on github.
Enhancing Articles Through Hyperlinks
© 2026
by Michael Comella
is licensed under Creative Commons Attribution-ShareAlike 4.0 International![]()
![]()
![]()